
¿Por qué los textos de IA suenan genéricos?
Si alguna vez has leído un texto generado por ChatGPT, Gemini u otro modelo de lenguaje y has sentido que “suena correcto pero vacío”, no estás solo. La sensación de uniformidad, de tono neutro y de falta de matiz no es una impresión subjetiva. Es el resultado directo del diseño estadístico de estos sistemas.
Los modelos actuales de lenguaje no están diseñados para la innovación literaria ni para la exploración estilística profunda. Están diseñados para maximizar la probabilidad estadística de la siguiente palabra. En otras palabras, buscan producir la secuencia más probable, no la más audaz.
Este principio estructural explica por qué muchos textos generados por IA parecen intercambiables entre sí.
La lógica estadística detrás del texto “plano”
Cuando un modelo de lenguaje genera una respuesta, no “piensa” como un humano. Evalúa miles de posibles tokens (palabras o fragmentos de palabras) y selecciona aquellos con mayor probabilidad condicional según el contexto previo.
Una estrategia común utilizada en este proceso es el greedy decoding (decodificación voraz). Este método selecciona, en cada paso, el token más probable sin considerar alternativas menos frecuentes pero potencialmente más ricas.
Aunque existen parámetros como temperatura o top-p que introducen variabilidad, la tendencia natural del sistema es minimizar la perplejidad. Esto implica reducir la incertidumbre estadística, favoreciendo estructuras previsibles y vocabulario de alta frecuencia.
El resultado es un texto seguro, claro, pero raramente sorprendente.
La arquitectura de la mediocridad estadística
El problema no es que la IA “no sepa escribir”. Es que su objetivo de optimización no es la creatividad, sino la coherencia estadística.
En un texto humano experto, la diversidad léxica suele ser alta. Se utilizan términos técnicos precisos, ambigüedades deliberadas, ironía, variaciones sintácticas y estructuras no lineales que requieren mayor esfuerzo cognitivo.
En contraste, un modelo de lenguaje tiende a:
-
Neutralizar fricción cognitiva.
-
Simplificar estructuras complejas.
-
Sustituir términos técnicos por equivalentes más frecuentes.
-
Repetir conectores previsibles.
-
Organizar la información en patrones estructurales similares.
Claudio Nastruzzi, profesor de la Universidad de Ferrara, ha descrito este fenómeno como “ablación semántica”: una degradación progresiva del contenido mediante la eliminación de matices de baja probabilidad estadística.
El sistema no busca profundidad. Busca consenso.
El impacto del aprendizaje por refuerzo humano (RLHF)
Otro factor clave es el entrenamiento mediante aprendizaje por refuerzo con retroalimentación humana.
Durante esta fase, evaluadores humanos califican respuestas según criterios como claridad, seguridad y cortesía. Naturalmente, los textos más directos, neutros y “seguros” obtienen mejores puntuaciones.
El modelo aprende que:
-
El lenguaje técnico especializado puede ser arriesgado.
-
La ironía puede ser malinterpretada.
-
Las estructuras complejas pueden generar confusión.
-
Las afirmaciones contundentes pueden ser penalizadas.
Como consecuencia, opta por el camino de menor fricción lingüística.
El sistema internaliza que la ambigüedad creativa es un riesgo.
Por qué la IA evita palabras “raras”
Cuando un experto escribe, suele emplear términos con baja frecuencia estadística pero alta precisión conceptual. Para un modelo, estos términos tienen menor probabilidad de aparición.
Ante dos opciones, el modelo tenderá a elegir:
-
Una palabra común con probabilidad alta.
-
En lugar de un término técnico exacto con probabilidad baja.
Este reemplazo estadístico diluye la fuerza del argumento y genera una homogeneización léxica.
Lo que se pierde no es información básica, sino densidad semántica.
El problema no es técnico, es de diseño
Humanizar el contenido generado por IA no es simplemente una cuestión de potencia computacional. Es una decisión de diseño.
Las grandes compañías priorizan:
-
Seguridad.
-
Generalización.
-
Control.
-
Reducción de alucinaciones.
Introducir mayor diversidad léxica o estructuras complejas incrementa la entropía del modelo. Y mayor entropía implica mayor riesgo de error.
Un modelo más creativo también puede ser más impredecible.
¿Se puede humanizar el contenido generado por IA?
Sí, pero con matices.
Existen estrategias posibles:
-
Ajustar parámetros de creatividad (temperatura).
-
Penalizar repetición semántica.
-
Incentivar exploración léxica.
-
Filtrar datasets hacia fuentes de alta densidad informativa.
-
Diseñar funciones de pérdida que premien baja frecuencia controlada.
Sin embargo, estas soluciones aumentan la probabilidad de alucinaciones o incoherencias.
En términos industriales, el equilibrio favorece estabilidad sobre originalidad.
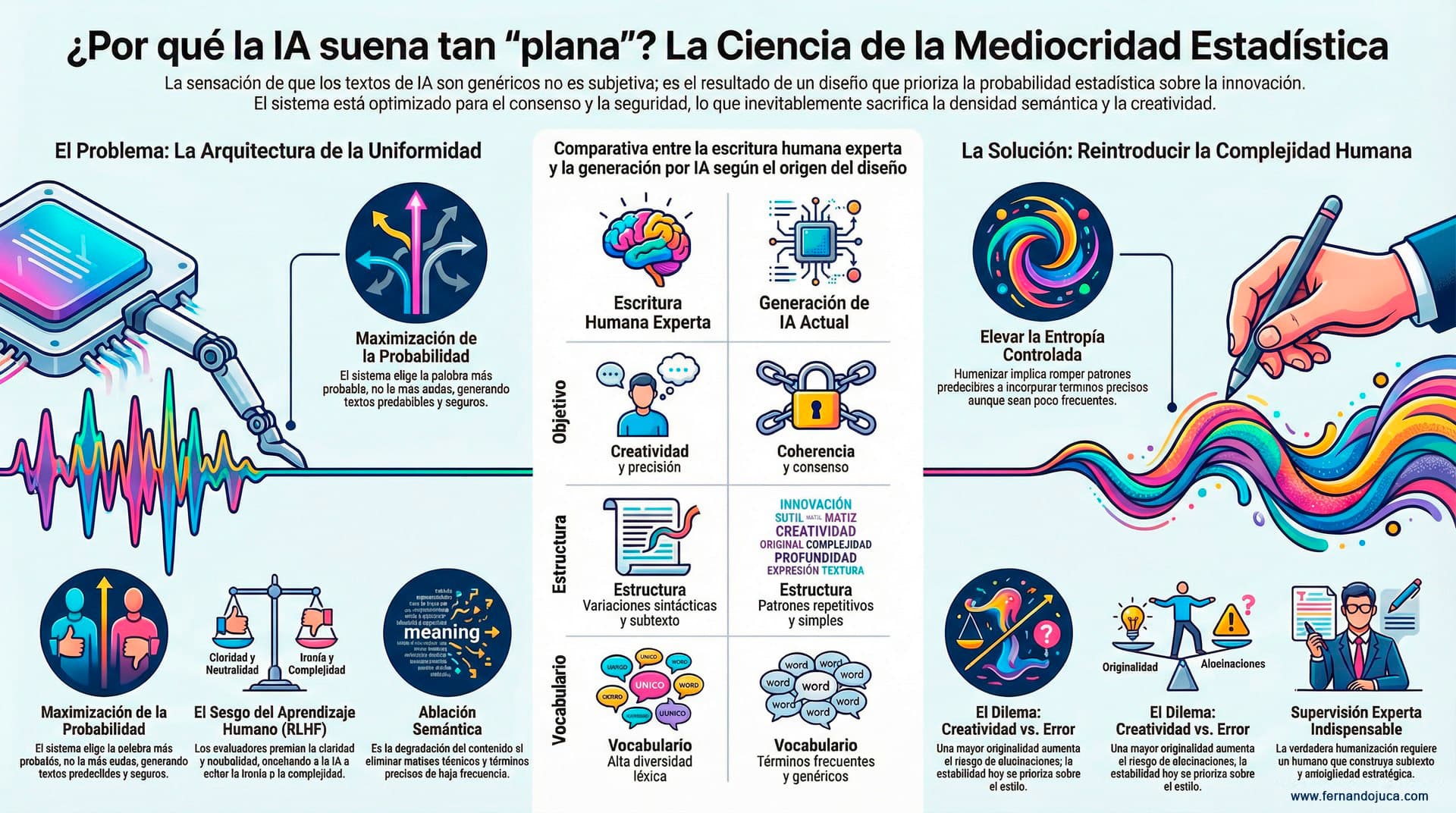
Humanizar no es “decorar”, es reintroducir complejidad
Humanizar un texto de IA implica:
-
Romper patrones previsibles.
-
Introducir variación estructural.
-
Incorporar matiz conceptual.
-
Utilizar términos precisos aunque sean menos frecuentes.
-
Permitir ambigüedad estratégica.
-
Construir subtexto.
En esencia, implica elevar la entropía controlada del discurso.
Pero ese movimiento exige supervisión experta.
¿Es el futuro inevitablemente genérico?
Las empresas tecnológicas enfrentan una tensión estructural:
-
Más creatividad implica más riesgo.
-
Más control implica más uniformidad.
En el contexto actual, la industria prioriza confiabilidad sobre innovación estilística. Un texto genérico pero correcto es preferible a uno creativo pero erróneo.
La “mediocridad estadística” no es una falla accidental. Es una consecuencia predecible del modelo de optimización.
Recuerde…
Los textos de IA suenan genéricos porque los modelos están diseñados para maximizar probabilidad, minimizar riesgo y satisfacer criterios de evaluación humana centrados en claridad y seguridad.
No es una limitación accidental. Es una arquitectura optimizada para consenso.
Humanizar el contenido no significa hacerlo “más bonito”. Significa reintroducir complejidad, matiz y densidad semántica en un sistema entrenado para simplificar.
La pregunta no es si la IA puede escribir mejor.
La pregunta es si estamos dispuestos a asumir el riesgo que implica permitirle hacerlo.
Preguntas frecuentes (FAQ)
1. ¿Por qué los textos de IA parecen repetitivos?
Porque los modelos priorizan palabras y estructuras con alta probabilidad estadística. Esto reduce variabilidad y genera patrones reconocibles.
2. ¿Qué es el greedy decoding?
Es una estrategia de generación de texto en la que el modelo elige en cada paso la palabra más probable, minimizando incertidumbre pero limitando creatividad.
3. ¿Humanizar contenido de IA aumenta el riesgo de errores?
Sí. Incrementar diversidad léxica y complejidad sintáctica puede aumentar la probabilidad de alucinaciones o inconsistencias.
4. ¿Se puede entrenar un modelo para ser más creativo?
Técnicamente sí, ajustando parámetros o funciones de entrenamiento, pero hacerlo implica sacrificar parte de la estabilidad y control que la industria prioriza actualmente.









